
Image credit: Ray-tracing benchmark image. (Source: Basemark)
CG may scale indefinitely.
Ray tracing and, more recently, path tracing, have been the goal of computer graphics (CG) developers for over four decades. In most cases, CG was dedicated to creating photorealistic images that were indistinguishable from real life. The exceptions were animations, fantasies, and special or visual effects known as VFX.[[i]]
As desirable — and in some medical and enterprise cases, essential — as ray tracing is, it is an unlimited consumer of compute resources. Theoretically, a ray-traced image is never finished, but the point of diminishing returns can be realized. When such a point is selected, the image will have some compromise of quality, but not enough to make it useless.
In 2018, NVIDIA introduced its RTX 4090 add-in board with the AD102 Ada GPU, which included the first integrated neural processing unit, which the company then called Tensor Cores. Along with the hardware breakthrough, the company introduced Deep Learning Super Sampling — DLSS software.[[ii]] DLSS was revolutionary in concept and implementation. The concept was simple to understand; the GPU would examine several real-time frames of a game and analyze the construction of the images using the NPU. Next, the image’s resolution would be reduced, and a ray-traced version of the analyzed image would be generated. Then, the new AI-created frames ray-traced image would be scaled back up and presented to the monitor. All that was done in less than 33ms, providing a playable ray-traced stream of images to the user. Over the past four years, NVIDIA has refined and redesigned the DLSS architecture, making it faster and more efficient and incorporating high-quality ray-tracing capabilities such as global illumination. As of this writing, the current version is 3.7.1, illustrating the interpretations and development of the revolutionary software. AMD and Intel have developed similar technologies. AMD calls their solution FidelityFX Super Resolution (FSR),[[iii]] and Intel calls theirs Xe Super Sampling (XeSS).[[iv]]
So now we have real-time ray tracing, and the long-out-of-reach, the so-called holy grail of CG, has been realized — and it gets better with every iteration and new GPU. During our luncheon at SIGGRAPH 2002, we asked our panel of experts at the time, “Are we done yet?” CG improvements in hardware and software had been advancing at an incredible rate, and many things that took a supercomputer and a few weeks were now being done in a day or less on regular workstations. But the resounding conclusion from our panels was “No! We’re far from done yet.”
Now flash forward 22 years — are we done yet?
We now have GPUs with 16 to 18,000 32-bit floating-point processors.
We have real-time ray tracing.
We have AI generative art and image processing software with AI support.
We have 4K to 8K 40-inch monitors and 65-inch and above 4K TVs.
We have desktop and notebook PCs that are more powerful than a supercomputer of 10 years ago.
Our PCs have 129GB of amazingly fast RAM, plus tens of gigabytes of super high-speed video memory.
What can’t we do with what we have? Surely we must have enough by now.
Maybe not….
In the 1980s, the renowned and eminent Dr. Jim Blinn introduced Blinn’s Law.[[v]] It states simply and elegantly: “As technology advances, rendering time remains constant.”
The conceit was that rendering time tends to remain constant, even as computers get faster, because (animators in Blinn’s example) prefer to improve quality, rendering more complex scenes with more sophisticated algorithms, rather than using less time to do the same work as before.
That being the case, is there an asymptote to Blinn’s Law? I asked him that once, and he gave me that charming smile of his and said, “Well, of course, but you and I won’t find it.”
Since then, I’ve posed the question to a few others.
When I asked Tim Sweeney, CEO and founder of Epic Games, he was less optimistic and said, “Many aspects of rendering are still very limited by shader performance, such as the ability to achieve a high frame rate at a high resolution, with geometry, lighting, and subsurface scattering detail as precise as your eyes can see. We could easily consume another 10× shader performance without running out of improvements.”
He continued: “There are a few details that are limited not by performance but by our lack of sufficiently powerful algorithms, such as rendering faces, face animation, body animation, character dialogue, and other problems that amount to simulating human intelligence, emotion, and locomotion. If you gave us an infinitely fast GPU today, we still couldn’t do humans that were indistinguishable from reality.
“Compared to past decades when we had no clear idea of how we’d ever solve those problems, nowadays we generally think that AI trained on vast amounts of human interaction data (which Epic will only ever do under proper license!) will be able to bridge the gap to absolute realism, possibly even by the end of the decade. I’m not sure how much GPU performance that will require. Perhaps not more than today’s GPUs.”
Darwesh Singh, founder and CEO of Bolt Graphics, offered a contrarian point of view: “In many industries, deep learning is used to approximate the result of real computation to reduce time to results, but the approximation is lower quality than real computation. The benefit is it’s faster because of the encoding but really lossy/inaccurate (also because of the encoding). The benefit is not so great because training takes a lot of data and compute resources, and inference is also pretty slow. People are trying to replace HPC simulations with AI models, but our GPU beats inference time with real computation and is more accurate!”
Singh further stated: “Adding more programmable cores to GPUs is not a great solution. Good utilization across tens of thousands of cores is hard to achieve. Adding that many cores drives large die sizes, and other GPU vendors are having trouble adding more cores, even with smaller nodes. It’s not infinite scaling (more cores clocked higher equals more power) by any means, and bigger chips have lots of design issues. Memory bandwidth needs to be so high that you need expensive and low-yield HBM, and then to achieve a good margin, you need to charge $20K–$30K for your part.
“Our idea (a third option versus more programmable cores and AI approximation) is to make hardware that is faster than inference without the side effect of training hell and statistical approximations. We have evidence this works really well — in many workloads, we achieve higher performance this way, power consumption decreases, code becomes easier to write, and compilers don’t have to work so hard trying to find low ROI optimizations.”
Fredric Servant, director of engineering at Autodesk, went a step further and gave me some test data. He told me, “In our collaboration with NVIDIA, we’ve seen significant speedups with the Ada architecture. The bottleneck really was shading at this point; I’m attaching benchmarks. The previous generation brought a 3× speedup on some scenes. I’m not sure we are close to asymptote yet.
“Moreover, these sample tests are not really representative of the shading complexity of production scenes. NVIDIA confided that the test scene we provided them had the most complex and costly shading. A production scene goes beyond the rendering of realistic surfaces with half a dozen textures directly plugged in to a single shader. There are often artistic adjustments, proceduralism, non-physical or non-photorealistic looks, and hard-to-render effects like scattering in hair or volumes. There’s still a lot to improve in those fields, and these are shading compute-intensive.”
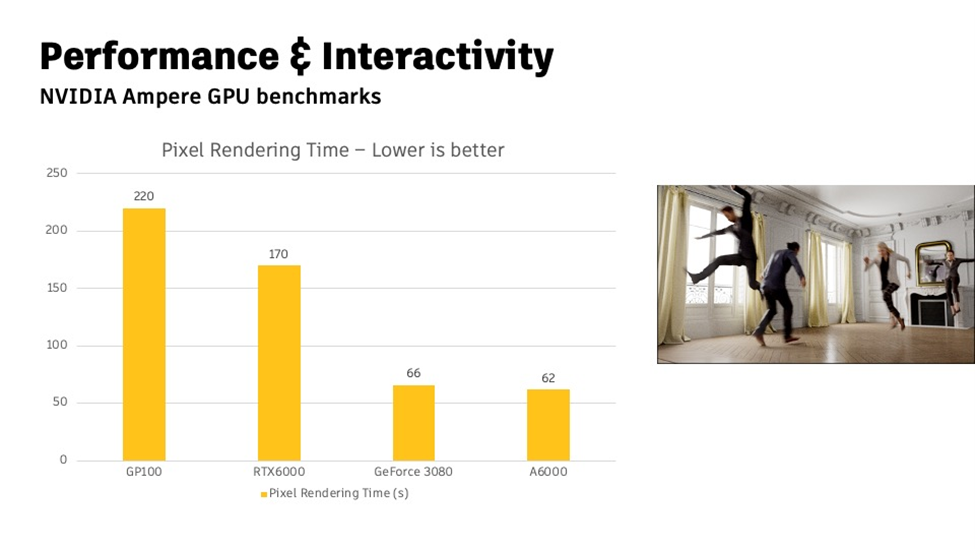
Figure 1. Autodesk Arnold rendering time on various GPUs. (Source: Autodesk)
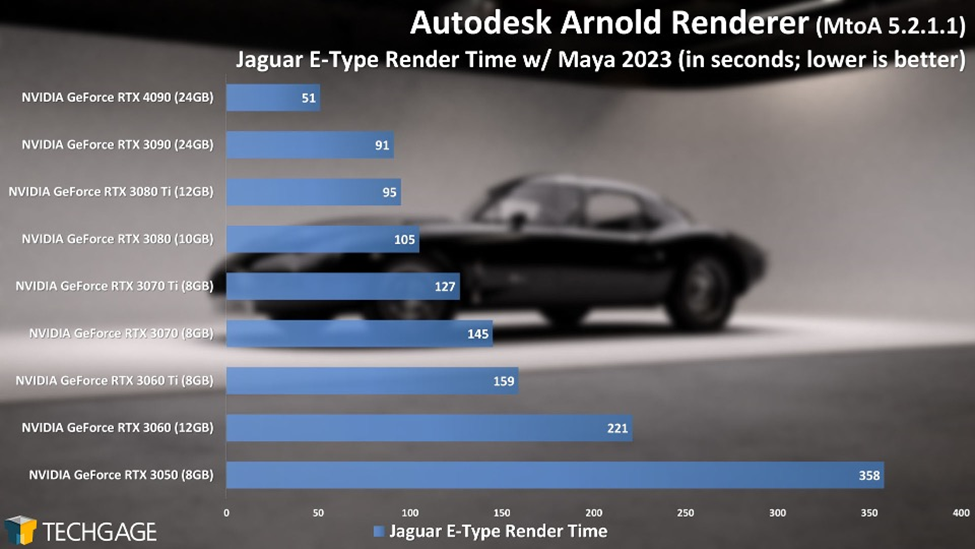
Figure 2. Autodesk’s Maya ray-tracing rendering time on various Nvidia GPUs. (Source: Techgage Networks Inc.)
Software developer Ton Roosendaal, creator of the open-source Blender software, seconded Servant’s comments and said, “Blender renders a lot faster on newer NVIDIAs, mainly because the software design allows it to be scaled up by adding compute units. How well AI can scale up this way? I think so … otherwise everyone wouldn’t buy NVIDIAs!”
So it seems, as the Talking Heads’ David Byrne said, “Same as it ever was, same as it ever was,” CG scales infinitely. (Byrnes didn’t say that second part, but I’m sure he’d agree.)

Source: Created by Jon Peddie via Openart.Ai
Twenty-two years, and we’re not done yet. I couldn’t be happier.
This article was authored by Jon Peddie of Jon Peddie Research.
[[i]] Visual effects, Wikipedia, https://en.wikipedia.org/wiki/Visual_effects
[[ii]] NVIDIA DLSS 3, https://www.nvidia.com/en-us/geforce/technologies/dlss/
[[iii]] AMD FidelityFX Super Resolution, https://www.amd.com/en/products/graphics/technologies/fidelityfx/super-resolution.html
[[iv]] What is Intel Xe Super Sampling (XeSS), https://www.intel.com/content/www/us/en/support/articles/000090031/graphics/intel-arc-dedicated-graphics-family.html
[[v]] Moltenbrey, Karen, Blinn’s Law and the Paradox of Increasing Performance. Computer Graphics World, https://www.cgw.com/Press-Center/Web-Exclusives/2013/Blinn-s-Law-and-the-Paradox-of-Increasing-Perfor.aspx



){kind=link}