

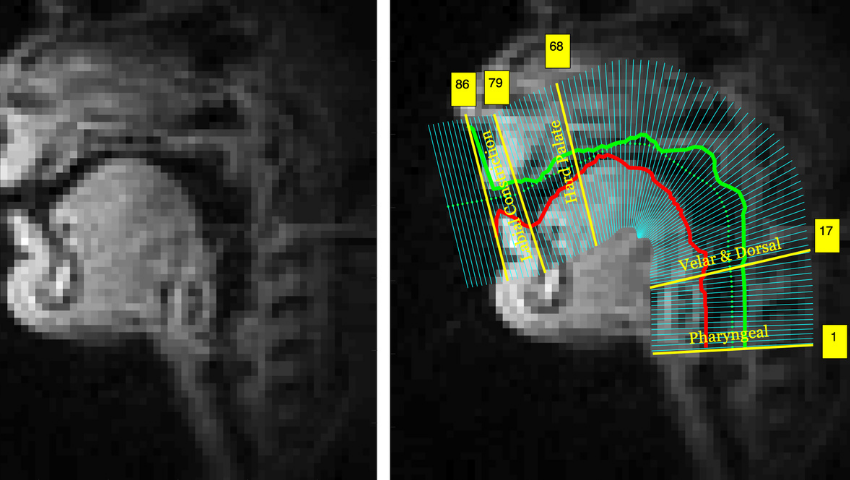
Frame of neutral emotion rtMRI video (left) and corresponding segmentation of lower and upper boundary of vocal tract (right) in four sub-regions: pharyngeal (1-17), velar and dorsal (18-68), hard palate (69-79), labial constriction (80-86). The video frames were extracted from the USC-TIMIT dataset. The vocal tract airway-tissue boundaries were extracted using the MATLAB software.
The SIGGRAPH 2021 Posters project “Silent Speech and Emotion Recognition From Vocal Tract Shape Dynamics in Real-time MRI” proposes a novel deep-learning framework that can automatically understand acoustic information present in the vocal tract shaping. This is then captured by real-time MRI during speech production and translated into text. We caught up with Laxmi Pandey and Ahmed Sabbir Arif to learn more about their SIGGRAPH 2021 Poster research and how it contributes to accessible communication. Plus, the researchers share what’s next for their real-time MRI study and how it can be applied to health care in the future.
SIGGRAPH: Share some background about your SIGGRAPH 2021 Poster. What inspired this research?
Laxmi Pandey and Ahmed Sabbir Arif (LP and ASA): We at the Inclusive Interaction Lab make computer technologies accessible to a wider range of people. In the lab, we often discuss how people with cognitive or physical disabilities have limited access to computer systems, mainly because they are excluded from the design process. Communication technologies, particularly, have not always been attentive to the needs of these user groups. Speech input (voice assistants like Amazon Alexa) is effective, but people with speech impairments are unable to communicate through vocalization due to a variety of speech or neurological disorders.
Although augmentative and alternative communication (AAC) devices try to synthesize speech, the process is slow and the vocalization sounds unnatural. Many also use unconventional means of input, such as head movements and eye blink and gaze. This prevents users from accessing modern computer systems and effectively communicating with other humans. We believe people with disabilities must have equal opportunity to benefit from the technological advances, which are often necessary in employment, educational, recreational, and other settings. This led us to explore the possibility of a new form of communication that can essentially help people with speech disorders communicate with humans and machines.
SIGGRAPH: In exploring the possibility of a new form of communication, your final Poster proposes a novel deep-learning framework that automatically understands acoustic information present in the vocal tract. How did you develop this framework?
LP and ASA: Most real-time magnetic resonance imaging (rtMRI)-based speech recognition models recognize one sub-word (i.e., one vowel-consonant-vowel combination or one phoneme) at a time. However, the majority of human-human or human-computer communications are at word- or phrase-level. This encouraged us to investigate whether it is possible to recognize one phrase at a time from vocal tract shaping during speech production. We developed an articulatory speech recognition model that can recognize a phrase being spoken from a silent video of vocal tract movements captured by rtMRI during speech production. This model uses deep 3D convolutional neural networks (CNNs), two bi-directional gated recurrent units (GRU), and a connectionist temporal classification (CTC) loss function to learn spatial-temporal visual features and sequential information simultaneously. Our preliminary model achieved about 60% phoneme accuracy rate at phrase-level, which is more accurate than the existing models.
SIGGRAPH: Talk a bit about how “Silent Speech and Emotion Recognition From Vocal Tract Shape Dynamics in Real-time MRI” analyzes variations in the geometry of vocal tract articulators with respect to emotion and gender. How does this factor advance previous research?
LP and ASA: While the proposed framework is novel, researchers have previously used rtMRI to study articulatory characteristics of emotional speech with vocal tract movement data from male and female speakers. But the findings of these works cannot be generalized to a wider audience due to their limited datasets (usually one speaker and/or a single word). Therefore, we re-investigated the rtMRI data of emotion-dependent vocal tract movements to compare different emotions and genders using a larger dataset to make it more generalizable. We conducted a study on MR images of 10 speakers (five male and five female) with two words spoken 56 times in three different emotions. To analyze, we measured the distortion of the vocal tract for different emotions — happy, angry, sad — by comparing the distortion of the vocal tract relative to neutral emotion.
SIGGRAPH: Did you encounter any obstacles when developing your research? If so, how did you overcome them?
LP and ASA: Usually, this type of research requires massive datasets to train a model. Although there are a few datasets available for this purpose, they are usually not sufficient to train a robust deep-learning model. Obtaining new datasets is challenging as it requires considerable effort, time, and resources. We addressed this issue by augmenting publicly available MRI data from the University of Southern California using simple transformations, such as horizontal mirroring of video frames. This augmentation step significantly enlarged the data size, which allowed the model to generalize more effectively, hence improving performance.
SIGGRAPH: What’s next for “Silent Speech and Emotion Recognition From Vocal Tract Shape Dynamics in Real-time MRI”? How might it be applicable in health care?
LP and ASA: The next step is to improve the model and explore applications of the model. There could be numerous applications. When the technology becomes more affordable and less invasive, it could be used to input text and communicate with various computer systems. It also can enable users to interact with public displays and kiosks without contact, which is of particular interest in the global spread of infectious diseases, such as the current COVID-19 situation. Most importantly, it could enable people with speech disorder, muteness, blindness, and motor impairment to input text and interact with various computer systems, increasing their access to these technologies.
Our model can transform current practices in health care for not only those with a speech disability but also people with situational impairments. Many patients lose their voice temporarily after a major surgery. Being in this situation for the first time, people with situational impairments arguably struggle more to communicate with their health care providers and loved ones, and the cost of miscommunication in such situations can be dire. Our system can mitigate this by providing them a means to “speak.”
SIGGRAPH: SIGGRAPH 2022 Posters submissions are underway. What advice do you have for someone planning to submit their own in-progress research to the SIGGRAPH conference?
LP and ASA: We strongly encourage students to submit posters on their research to SIGGRAPH, not only to disseminate and showcase their work but also to receive feedback from the diverse SIGGRAPH community, which helped us shape the next direction of this project. Our advice is to start preparing the documents early. Due to the strict page limit, it takes time to decide what must stay on and what must go, and to make sure the document is compact but has all necessary details. We also encourage them to prepare a graphical poster and a demo, if possible, to attract the audience to ask questions and engage in conversations.
Calling all students, researchers, artists, enthusiasts, and practitioners! SIGGRAPH 2022 Posters submissions are open through 26 April. Submit your work for a chance to showcase your thought leadership and receive feedback from the global SIGGRAPH community.
 Laxmi Pandey is a Ph.D. student of electrical engineering and computer science at the University of California, Merced, where she works at the Inclusive Interaction Lab. Her research focuses on multiple areas, including natural language processing, audio-visual speech recognition, and applied artificial intelligence. Her aim is to design and develop effective and accessible communication technologies for mobile devices. She has received many awards for her research activities, including the Fred and Mitzie Ruiz Fellowship, the Hatano Cognitive Development Research Fellowship, ACM-W Scholarship, and SIGIR Travel Grants. She received her Master’s in electrical engineering from IIT Kanpur, India.
Laxmi Pandey is a Ph.D. student of electrical engineering and computer science at the University of California, Merced, where she works at the Inclusive Interaction Lab. Her research focuses on multiple areas, including natural language processing, audio-visual speech recognition, and applied artificial intelligence. Her aim is to design and develop effective and accessible communication technologies for mobile devices. She has received many awards for her research activities, including the Fred and Mitzie Ruiz Fellowship, the Hatano Cognitive Development Research Fellowship, ACM-W Scholarship, and SIGIR Travel Grants. She received her Master’s in electrical engineering from IIT Kanpur, India.
 Ahmed Sabbir Arif is an assistant professor of computer science and engineering at the University of California, Merced, where he leads the Inclusive Interaction Lab. His research program is interdisciplinary, spanning multiple areas including computer science, cognitive science, human factors, virtual reality, accessibility, and applied artificial intelligence. His mission as a researcher is to make computer systems accessible to everyone by developing intuitive, effective, and enjoyable input and interaction techniques. He has received many awards for his research activities, including the Hellman Fellowship, the Michael A. J. Sweeney Award, and the CHISIG Gitte Lindgaard Award. He received his Ph.D. in computer science from York University, and also holds an M.Sc. from Lakehead University and a B.Sc. from Trent University in computer science.
Ahmed Sabbir Arif is an assistant professor of computer science and engineering at the University of California, Merced, where he leads the Inclusive Interaction Lab. His research program is interdisciplinary, spanning multiple areas including computer science, cognitive science, human factors, virtual reality, accessibility, and applied artificial intelligence. His mission as a researcher is to make computer systems accessible to everyone by developing intuitive, effective, and enjoyable input and interaction techniques. He has received many awards for his research activities, including the Hellman Fellowship, the Michael A. J. Sweeney Award, and the CHISIG Gitte Lindgaard Award. He received his Ph.D. in computer science from York University, and also holds an M.Sc. from Lakehead University and a B.Sc. from Trent University in computer science.






vashishti
great post and valuable, I like this post, I thought that word press is a very good option for a blog, very nice article, thanks for sharing.